




【华e生活大唐编译】在任何时候,最强大的人工智能模型是什么?查看排行榜。
最近几个月,在网上公开发布的人工智能模型社区排名人气飙升,让人们可以实时了解各大科技公司之间正在进行的人工智能霸主争夺战。
每个排行榜都会根据AI模型完成特定任务的能力来追踪其最先进的AI模型。AI模型的本质是一组用代码包装的数学方程,旨在实现特定目标。
一些新进入者,如谷歌的Gemini(前身为Bard)和总部位于巴黎的初创公司Mistral AI的Mistral- medium,已经在人工智能社区激起了兴奋,并争夺排名靠前的位置。
然而,OpenAI的GPT-4继续占据主导地位。
“人们关心的是技术水平,”斯坦福大学(Stanford University)计算机科学博士生、聊天机器人竞技场(Chatbot Arena)排行榜的联合创始人Ying Sheng说。“我认为人们其实更希望看到排行榜发生变化。这意味着游戏仍然存在,还有更多需要改进的地方。”
排名基于测试,这些测试确定了人工智能模型的一般能力,以及哪个模型可能最适合特定用途,比如语音识别。这些测试有时也被称为基准测试,根据人工智能的声音声音或人工智能聊天机器人的反应等指标来衡量人工智能的表现。
随着人工智能的不断发展,这种测试的演变也很重要。
斯坦福大学以人为中心的人工智能研究所(Institute of Human-Centered Artificial Intelligence)的研究主任瓦妮莎·帕利(Vanessa Parli)说,“这些基准并不完美,但就目前而言,这是我们评估这个系统的唯一方法。”
该研究所编制了斯坦福大学的人工智能指数,这是一份年度报告,追踪人工智能模型在各种指标上的技术表现。Parli说,去年的报告考察了50个指标,但只包括了20个,今年将再次剔除一些较老的指标,以突出更新、更全面的指标。
排行榜还提供了一个关于有多少模型正在开发的一瞥。开源机器学习平台hug Face建立的开放LLM(大型语言模型)排行榜,截至2月初,已经对4200多个模型进行了评估和排名,这些模型都是由其社区成员提交的。
这些模型根据七个关键基准进行跟踪,旨在评估阅读理解和数学解决问题等各种能力。评估包括对这些模型在小学数学和科学问题上的测试,测试他们的常识性推理,以及衡量他们重复错误信息的倾向。一些测试提供多项选择答案,而另一些则要求模型根据提示生成自己的答案。
访问者可以看到每个模型在特定基准上的表现,以及它的总体平均得分。目前还没有任何一种模型在任何基准测试中获得满分100分。smaugg – 72b是由旧金山初创公司Abacus创建的一种新的人工智能模型。最近,人工智能成为第一个平均分超过80分的机器人。
许多llm在这些测试中的表现已经超过了人类的基准水平,这表明研究人员所说的“饱和”。拥抱脸的联合创始人兼首席科学官托马斯·沃尔夫(Thomas Wolf)说,当模型的能力提高到超出特定基准测试的程度时,通常会发生这种情况——就像一个学生从初中升入高中一样——或者当模型记住了如何回答某些测试问题时,这种概念被称为“过度拟合”。
当这种情况发生时,模型在以前执行的任务中表现良好,但在新情况或旧任务的变化中却表现不佳。
“饱和并不意味着我们总体上变得‘比人类更好’,”沃尔夫在一封电子邮件中写道。“这意味着,在特定的基准测试中,模型现在已经达到了当前基准测试无法正确评估其能力的程度,因此我们需要设计新的模型。”
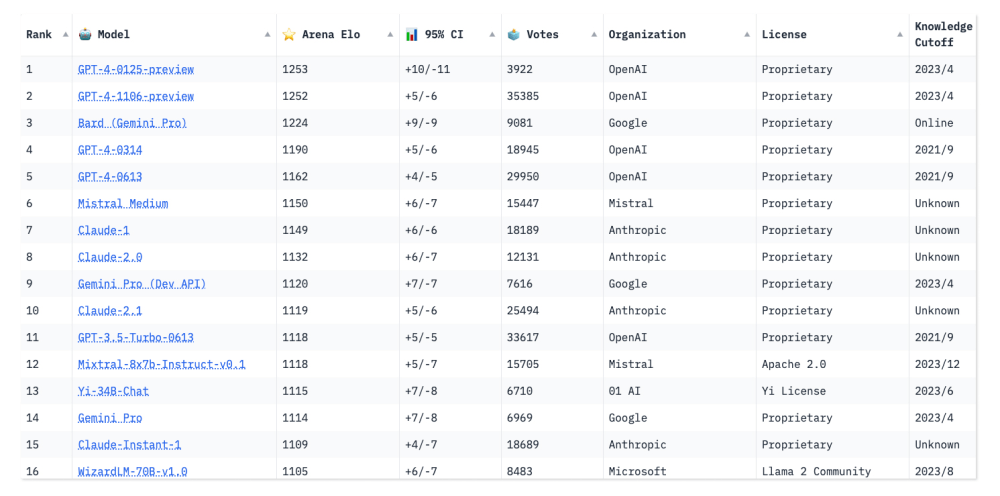
一些基准测试已经存在多年了,对于新llm的开发人员来说,在这些测试集上训练他们的模型以保证在发布时获得高分变得很容易。聊天机器人竞技场(Chatbot Arena)是一个由校际开放研究组织大型模型系统组织(Large Model Systems Organization)创建的排行榜,旨在通过使用人工输入来评估人工智能模型,从而解决这一问题。
Parli说,这也是研究人员希望在测试语言模型的方式上具有创造性的一种方式:通过更全面地判断它们,而不是一次只看一个指标。
她说:“特别是因为我们看到更多传统的基准已经饱和,引入人工评估让我们能够了解计算机和更多基于代码的评估所不能达到的某些方面。”
“聊天机器人竞技场”允许参观者向两个匿名的人工智能模型提出任何问题,然后投票决定哪个聊天机器人能给出更好的回答。
到目前为止,它的排行榜根据30多万张人类投票对大约60个模型进行了排名。据该网站的创建者称,自从该排名推出不到一年以来,该网站的访问量大幅增加,如今Arena每天都能获得数千张选票,而且该平台收到了太多添加新模型的请求,以至于无法容纳所有这些人。
Chatbot Arena的联合创始人蒋伟林(Wei-Lin Chiang)是加州大学伯克利分校(University of California-Berkeley)计算机科学专业的博士生。他说,该团队进行的研究表明,众包投票产生的结果几乎和聘请人类专家测试聊天机器人一样高质量。他说,不可避免地会有异常值,但该团队正在开发算法,以检测匿名选民的恶意行为。
尽管基准测试很有用,但研究人员也承认,它们并非包罗万象。hug Face的联合创始人沃尔夫写道,即使一个模型在推理基准上得分很高,但在分析法律文件等特定用例时,它可能仍然表现不佳。
他补充说,这就是为什么一些业余爱好者喜欢通过观察人工智能模型在不同环境中的表现来进行“氛围检查”,从而评估这些模型如何成功地与用户互动,保持良好的记忆和保持一致的个性。
尽管基准测试存在缺陷,但研究人员表示,测试和排行榜仍然鼓励人工智能开发人员进行创新,他们必须不断提高标准,以跟上最新的评估。





