




来源:信息时代
今天,《纽约时报》对OpenAI和微软正式提起诉讼,指控其未经授权就使用纽约时报内容训练人工智能模型。此案可能是人工智能使用知识版权纠纷的分水岭。
今天,OpenAI和微软正式被《纽约时报》起诉!索赔金额,达到了数十亿美元。
指控内容是,OpenAI和微软未经许可,就使用纽约时报的数百万篇文章来训练GPT模型,创建包括ChatGPT和Copilot之类的AI产品。
并且,要求销毁“所有包含纽约时报作品的GPT或其他大语言模型和训练集”。酝酿了几个月,该来的终于来了。
此案涉及到的,是AI技术和版权法之间的复杂关系。大模型爆火之后,业界一直未能有明确的立法,对于AI侵犯版权给出界定。
纽约时报打响的这一炮,可以说是迄今为止规模最大、最具有代表性和轰动性的案例。
在整个生成式AI历史上,这必定是一件具有重大意义的事件,标志着人工智能和版权的分水岭。
起诉文件中,《纽约时报》的关键争议之一是ChatGPT训练权重最大的数据集——公共爬虫网站Common Crawl。其中2019年数据快照中,NYT的内容占比1亿个token。

纽约时报甩出的证据,让OpenAI哑口无言。
左边是GPT-4输出的句子,右边是纽约时报的原文,红色是重叠的部分。这种程度的逐字抄袭,简直是让人倒吸一口凉气。

图片OpenAI这一关,怕是难过了。
GPT-4被曝照搬原文
起诉书明确提出OpenAI侵犯版权的指控,并强调了《纽约时报》的文章和ChatGPT输出内容之间高度相似性。
“被告试图搭纽约时报对新闻业巨额投资的便车,无偿使用纽约时报的内容来创造它的替代品,并从中窃取读者。”
文件中,NYT提供了许多关键事实。比如,NYT是Common Crawl中用于训练GPT的最大的专有数据集。
从下表中,可以看出有1750亿参数的GPT-3训练数据中,大部分的数据集都来自Common Crawl,所占权重高达60%。

下图中,是由501非营利组织Common Crawl提供的“网络副本”。
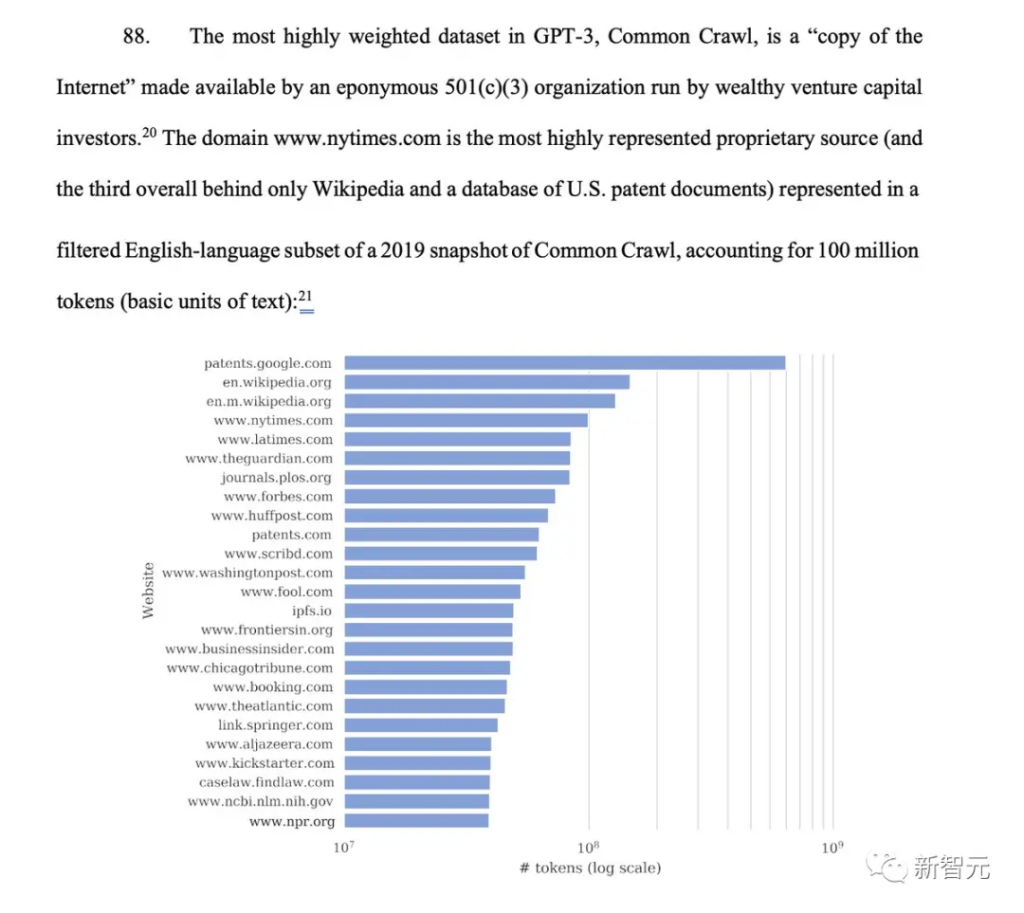
在Common Crawl 2019年快照的过滤英语子集中,域名www.nytimes.com是代表度最高的专有来源(总体排名第三,仅次于维基百科和美国专利文件数据库),占1亿个token。
图片OpenAI发言人表示,公司一直在推进与纽约时报的洽谈,对于这起诉讼感到惊讶和失望。
我们尊重内容创作者和所有者的权利,并致力于与他们合作,确保他们从人工智能技术和新的收入模式中受益。
我们希望能找到一种互惠互利的合作方式,就像我们与许多其他出版商所达成的合作。
这个案件之所以极富争议性,是因为许多生成式AI公司训练模型时,对于受版权保护内容的使用程度,这是个模糊的灰色地带。





