



来源:极目新闻
据环球网科技4日综合报道:斯坦福大学AI团队推出的Llama3-V模型,被指套壳抄袭了国内清华大学与面壁智能联合开发的开源模型“小钢炮”MiniCPM-Llama3-V 2.5。随着事件的发酵,斯坦福Llama3-V团队的两位核心成员,Siddharth Sharma(森德哈斯·沙玛)和Aksh Garg(阿克沙·加格),在社交平台上发表了正式道歉声明,承认在Llama3-V模型的开发过程中存在学术不端行为,并向面壁MiniCPM团队表达了诚挚的歉意。
Aksh Garg在声明中表示:“首先,我们要向MiniCPM原作者道歉。我、Siddharth Sharma以及Mustafa(穆斯塔法)共同负责发布了Llama3-V。Mustafa负责编写了该项目的代码,但自昨日起,我们已无法与他取得联系。我与Siddharth主要负责协助Mustafa推广该模型。我们两人都曾查阅最新的研究论文,以核实该项目的新颖性,但我们并未被告知或意识到OpenBMB之前的任何相关工作。我们对此深感抱歉,并对自己未能充分验证项目的原创性表示失望。我们愿为所发生的一切承担全部责任,并已决定撤下Llama3-V模型。再次为我们的行为向所有人道歉。”
团队成员此前辩称“只是架构相似”
据此前报道:斯坦福大学AI团队疑似抄袭中国大模型创业公司的消息引发业内高度关注。
6月3日,面壁智能CEO李大海与联合创始人刘知远先后发文,回应开源模型被斯坦福大学AI团队抄袭一事。李大海表示:“我们对这件事深表遗憾。一方面感慨这也是一种受到国际团队认可的方式,另一方面呼吁大家共建开放、合作、有信任的社区环境。”“我们希望团队的好工作被更多人关注与认可,但不是以这种方式。”
5月29日,一个来自斯坦福的AI团队开始在网络上宣传500美元就能训练出一个SOTA 多模态模型,该模型名为Llama3-V,作者声称Llama3-V比GPT-4V、Gemini Ultra、Claude Opus 性能更强。

由于该团队成员拥有斯坦福、特斯拉等亮眼背景,Llama3-V项目很快冲到HuggingFace (一个开发者社区和平台)首页,并引发开发者群体的关注。
一位用户在社交平台X与HuggingFace上质疑llama-3V 是否套壳MiniCPM-Llama3-V 2.5 ,后者为面壁智能推出的开源端侧多模态模型,于2024年5月21日发布。
Llama-3V 团队彼时回应,他们只是使用了 MiniCPM-Llama3-V 2.5 的tokenizer(分词器,自然语言处理中的一个重要组成部分),并在 MiniCPM-Llama3-V 2.5 发布前就开始了这项工作。但团队并未解释如何做到在MiniCPM-Llama3-V 2.5发布之前就获取详细tokenizer的具体方式。
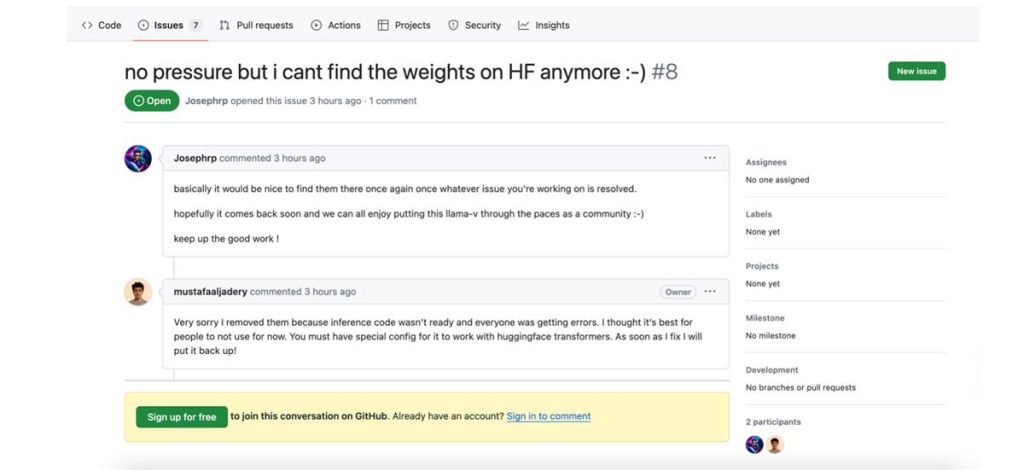
但随后,关于上述AI团队抄袭的声音越来越多。据HuggingFace页面显示,最初Llama3-V的作者在上传代码时直接导入了MiniCPM-V 的代码,然后将名称更改为 Llama3-V。但作为其中一个作者,Mustafa Aljadery(穆斯塔法·阿尔贾德里)并不认为该行为属于抄袭。他发文称,llama3-v推理存在bug,只是架构相似,并不是抄袭。

AI团队两成员系斯坦福大学本科生
在李大海看来,另一证据在于Llama3-V同样使用了面壁智能团队新设置的清华简识别能力(清华大学于2008年7月收藏的一批战国竹简),且呈现的做错案例都与MiniCPM一模一样,而这一训练数据尚未完全公开。李大海称,这项工作是团队同学耗时数个月,从卷帙浩繁的清华简中一个字一个字扫描下来,并逐一进行数据标注,融合进模型中的。更加微妙的是,两个模型在高斯扰动验证(一种用于验证模型相似性的方法)后,在正确和错误表现方面都高度相似。
公开资料显示,斯坦福Llama3-V团队两位成员是来自斯坦福大学的本科生,曾发表多篇机器学习领域论文,实习经历包括了AWS、SpaceX等。
刘知远对此事评论称,人工智能的飞速发展离不开全球算法、数据与模型的开源共享,让人们始终可以站在SOTA的肩上持续前进。面壁开源的 MiniCPM-Llama3-V 2.5 就用了最新的Llama3 作为语言模型基座。而开源共享的基石是对开源协议的遵守,对其他贡献者的信任,对前人成果的尊重和致敬,Llama3-V团队无疑严重破坏了这一点。他们在受到质疑后已在Huggingface删库,该团队三人中的两位也只是斯坦福大学本科生,未来还有很长的路,如果知错能改,善莫大焉。





